

【Google新検索アルゴリズム MUVERA】
個人ブログと大規模サイトへの影響
Google検索アルゴリズムは常に進化しています。
その変化はウェブサイト運営者やコンテンツクリエイターにとって、とても大きな課題です。
近年、Googleは「MUVERA(MUlti-VEctor Retrieval Algorithm)」という新しい検索アルゴリズムを発表しました。これは単なるアップデートではなく、検索エンジンの「思考方法」そのものを変える技術と言われています。
2025年6月30日から7月17日にかけて展開されたGoogleコアアルゴリズムアップデートは、このMUVERAアルゴリズムの導入と深く関連していると見られています。今回のアップデートは、検索結果に顕著な変動を引き起こし、多くのウェブサイトに影響を与えました。

本記事では、
- MUVERAがどのような技術で、なぜこの新しい検索技術が必要とされているのか?
- この革新的なアルゴリズムと最新のコアアップデートが個人ブログや大規模サイトにどのような影響を与えるのか?
- 今後のSEO対策において何が重要になるのか?
を専門家の見解も交えながら解説していきます。
MUVERAの登場と今回のコアアップデートは、ユーザーが情報にアクセスする方法、情報収集する方法を再定義する、新時代の幕開けになると思います。
新しい検索技術が必要な理由
検索技術が抱える「言葉の壁」
従来の検索システムはキーワードの表面的な一致を重視しており、ユーザーの「意図」を完全に理解することはできません。「○○○ △△△ □□□」と検索しても、単語が含まれるページが上位に来るだけでした。
言葉を「数値」に変えるテクノロジーの進化
「ベクトル埋め込み(Vector Embedding)」技術により、言葉や文章を多次元空間上の「数値ベクトル」として表現できるようになりました。意味的に似たものは近く、似ていないものは遠く配置されるため、コンピュータが言葉の「意味」を数学的に理解可能になっています。
「マルチベクトル」の登場と課題
2020年に登場した「ColBERT」は、ひとつの言葉や文章に対して複数のベクトルを生成する「マルチベクトルモデル」を導入し、検索精度を向上させました。しかし、計算コストが急増し、大規模な検索システムでの実用化が困難になっています。
精度と速さを両立させる「MUVERA」

MUVERAの核心は、複雑な計算をシンプルに!
MUVERA(Multi-Vector Retrieval Algorithm)は、ColBERTのような「マルチベクトルモデル」の高い精度を維持しつつ、従来の「単一ベクトル検索」と同等の速度で処理できるように開発されました。
複雑な多ベクトル検索の課題を「既存の最適化された単一ベクトル検索の問題に変換する」という画期的なアイデアで、Googleが培ってきた高速検索インフラを活用できます。
マルチベクトルを「一本化」する技術「FDE」
MUVERAの技術的な要となるのが「Fixed Dimensional Encoding(FDE)」技術。
これは、複数のベクトルで表現されていた情報を、固定長の単一ベクトルに「圧縮」、「集約」するものです。元のマルチベクトルが持っていた情報(類似度など)を失うことなく、計算効率を劇的に向上させます。
どんなデータも「同じように」機能する強み
MUVERAは「データ非依存性」を持ちます。
FDEの変換プロセスが特定のデータセットの性質に縛られないため、日々データが変化するネット環境でも安定した高い性能を発揮できる。
技術的なつながり「MUVERAとColBERT」
ColBERTの革新が検索精度を飛躍的に向上
ColBERTは、クエリと文書を別々に処理し、「スコアリング段階」で関連性を評価する「Late Interaction(後期相互作用)」手法を採用し、検索時の計算負荷を削減しつつ、精度を向上させました。
きめ細やかな関連性評価「MaxSim」
ColBERTの精度向上に貢献したのが「MaxSim(Maximum Similarity)」スコアリング手法。
クエリ内の各単語と文書内の単語の類似度を計算し、最も類似度が高いものを選び出すことで、文脈をより正確に捉えます。
ColBERTの「遅さ」という弱点
マルチベクトルモデル特有の計算コストの問題があり、文書あたりのベクトル数が膨大になるため、処理速度が遅く、大規模な検索システムへの導入が困難でした。
特にMaxSimのような非線形計算は多くのリソースを必要としました。
計算コスト問題を解決するMUVERAのブレークスルー
複雑さを「単純な問題」へ
MUVERAは、ColBERTの計算複雑性問題を、根本から解決するアプローチを取りました。
マルチベクトル間の複雑な類似度計算を「単一ベクトル同士の類似度計算(Maximum Inner Product Search: MIPS)」という高度に最適化されている問題に変換することで、遅延の原因となる複雑な計算が、既存の高速アルゴリズムを活用できる形にして、性能向上を実現しました。
段階的な進化プロセス「FDE生成の裏側」
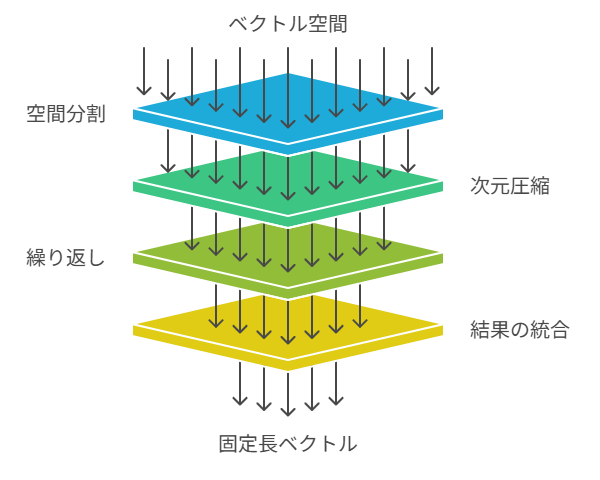
MUVERAのFDEは、4つのステップを経て生成されます。
- 空間の分割:ベクトルが格納されている空間を、数学的な手法(SimHashなど)を用いて小さな「バケット」に分割
- 次元の圧縮:各バケット内の複数のベクトルを代表的な一つのベクトルに集約(次元削減)
- 複数回の繰り返し:高い精度を得るために、分割・集約プロセスを異なる条件で複数回繰り返す。
- 最終的な単一ベクトル生成:複数の結果を統合し、最終的な固定長ベクトル(FDE)を生成。
理論的保証付きの性能
MUVERAのFDEは、数学的に「元のマルチベクトル類似度に対して、指定された誤差εの範囲内で近似できる」ことが証明されています。
これは、単なる経験則ではなく、理論的に裏付けられた確かな性能向上です。
数値で見る驚異的なパフォーマンス
検索速度が10倍に!?
MUVERAによる性能向上は、具体的な数値で見ていきます。
Google Researchの発表によると、従来の最先端手法と比較して、検索精度を平均10%向上させながら、検索速度を90%削減(つまり10倍高速化)したとのことです。これは、大規模な検索システムにおいて、ユーザー体験を劇的に改善する可能性を秘めている。
検索精度と速度の「トレードオフ」を解消
従来の検索システムでは、検索精度を高めようとすると処理速度が犠牲になり、逆に速度を優先すると精度が低下するという「トレードオフ」の関係でした。MUVERAは、この長年の課題を解決し、高精度と高速処理を両立させた。これは、検索技術の歴史において画期的な進歩。
2025年6月~7月 GoogleコアアプデとMUVERA
2025年6月30日から7月17日にかけて、Googleは新たなコアアルゴリズムアップデートを展開しました。このアップデートは、SEO専門家の間で、MUVERAアルゴリズムと関連しているようです。
Googleは公式には特定のアルゴリズム変更について詳細を明かしませんが、今回のアップデートによる変動は、MUVERAが目指す「ユーザーの意図理解の深化」と「コンテンツの質重視」の方向性を強く示唆しています。
アップデートの背景とMUVERAの役割
今回のコアアップデートは、MUVERAが実現する「マルチベクトル検索の高速化と高精度化」が、実際の検索ランキングに反映され始めた結果であると考えられます。
従来の「キーワードマッチング」に加えて、コンテンツ全体の意味や文脈、ユーザーの検索意図との合致度がより高度に評価されるようになったことで、検索結果の質が向上したと見られています。
変動と影響
アップデート期間中に注目されたのは、特定のニッチな分野や専門性の高い個人ブログ、中小規模のサイトが検索上位に浮上するケースが報告されたことです。
これは、MUVERAがロングテールキーワードや複雑な検索クエリに対するユーザーの真の意図をより正確に捉え、それに応える質の高いコンテンツを適切に評価した結果であると推測されます。
一方で、キーワードの詰め込みや低品質なコンテンツを量産していたサイトは、順位を大きく落とす傾向が見られました。
ヘルプフルコンテンツとE-E-A-Tの重要性の再確認
今回のアップデートは、Googleが以前から提唱している
- ヘルプフルコンテンツ(Helpful Content)
- E-E-A-T(経験、専門性、権威性、信頼性)
の重要性を改めて強調する形となりました。
MUVERAによってユーザーの意図理解が深まることで、真にユーザーの役に立つ、信頼できる情報源からのコンテンツがより優遇される傾向が強まりました。小手先のSEOテクニックではなく、本質的なコンテンツの質とユーザー体験の向上が、今後のSEO戦略の核となることを示しています。
MUVERAとコアアップデートが個人ブログに与える影響
MUVERAの導入と今回のコアアップデートは、個人ブログにとって追い風となる可能性があります。従来のキーワードマッチングに依存したSEO戦略から、ユーザーの検索意図を深く理解し、質の高いコンテンツを提供する方向へとシフトすることで、個人ブログでも大規模サイトと競合できる機会が増えるとされています。
専門性とニッチなコンテンツの評価向上
MUVERAは、マルチベクトル検索の特性により、より複雑なクエリやニッチなテーマに対するユーザーの意図を正確に捉えることができます。
今回のコアアップデートで観測されたように、特定の分野に特化した専門性の高い個人ブログや、独自の視点を持つニッチなコンテンツが、これまで以上に評価されるようになったそうです。
キーワードの網羅性よりも、コンテンツの深さや独自性が重要視されています。
ロングテールキーワードの重要性増大
MUVERAは、検索回数が少ないニッチな検索クエリ(ロングテールキーワード)においても、ユーザーの意図をより正確に捉えた検索結果の向上を期待できます。
個人ブログは、大規模サイトがカバーしきれないような特定のニッチなテーマやロングテールキーワードに特化することで、検索上位に表示されるチャンスが増えます。
特定の興味を持つユーザー層からのアクセス増加が見込めます。
小手先のSEOテクニックの無力化
キーワードの詰め込みや、内容の薄い記事を量産するような小手先のSEOテクニックは、MUVERAの導入と今回のコアアップデートにより効果が薄れると予想されます。
MUVERAは、コンテンツの質とユーザーの意図への合致度を重視するため、真に価値のある情報を提供しないサイトは評価されにくくなります。
個人ブロガーは、読者の問題解決や情報ニーズに応える必要があります。
MUVERAとコアアップデートが大規模サイトに与える影響
大規模サイトは、MUVERAの導入と今回のコアアップデートにより、その広範なコンテンツと権威性をさらに活かすことができる一方で、コンテンツ戦略の再考を迫られる可能性があります。
網羅性と信頼性のさらなる評価
MUVERAは、ユーザーの複雑な検索意図を理解する能力が高まるため、広範なテーマを網羅し、かつ信頼性の高い情報を提供する大規模サイトは、その優位性をさらに強固にする可能性があります。特に、E-E-A-T(経験、専門性、権威性、信頼性)の原則に沿ったコンテンツは、今回のコアアップデートでも高く評価される傾向が見られました。
コンテンツの品質とユーザー体験の最適化
大規模サイトは、膨大なコンテンツを抱えているため、個々のコンテンツの品質とユーザー体験の最適化が重要になります。MUVERAはユーザーの意図を深く理解するため、サイト全体の情報構造やナビゲーション、コンテンツの分かりやすさなど、ユーザーが求める情報にスムーズにたどり着けるような設計が求められています。単なるキーワードの羅列ではなく、ユーザーの疑問を完全に解決するような包括的なコンテンツが、今回のアップデートでも評価されました。
技術的SEOの継続的な重要性
MUVERAはセマンティック検索の精度を向上させますが、大規模サイトにおいては、依然として技術的SEOの重要性は高いです。
- ページのクロール性
- インデックス可能性
- サイト速度
- モバイルフレンドリー性
など、基本的な技術的要素が適切に最適化されていることが、MUVERAによる評価を最大限に引き出すための前提となります。
特に、大規模なサイト構造を持つ場合、これらの技術的側面が検索パフォーマンスに与える影響は大きく、今回のコアアップデートでもその重要性が再確認されました。
既存コンテンツの再評価と最適化
MUVERAの導入と今回のコアアップデートにより、既存の大量のコンテンツがどのように評価されるかを再評価し、必要に応じて最適化する作業が重要になります。キーワード最適化に偏っていたコンテンツは、ユーザーの意図に合致するように内容を改善したり、より深い情報を提供するように拡充したりする必要があります。
専門家の見解と今後のSEO対策
MUVERAの登場と2025年6月~7月のコアアップデートは、SEO業界の専門家たちからも注目を集めています。多くの専門家が、今回のアップデートがMUVERAが目指す「検索の質」を重視するGoogleの方向性をさらに強化するものと見ています。
検索意図の深掘りとコンテンツの「文脈」の重要性
専門家によると、MUVERAと今回のコアアップデートがユーザーの複雑な検索クエリの価値を高めると指摘しています。これは、単なるキーワードの羅列ではなく、コンテンツ全体の「文脈」や「ニュアンス」がこれまで以上に重要になることを意味します。
ユーザーがその検索に至った背景にある「悩み」「願望」「目的」を深く洞察し、そのすべてに先回りして応えるような、満足度の高いコンテンツだけが評価される時代になるでしょう。
E-E-A-T(経験・専門性・権威性・信頼性)のさらなる強化
MUVERAと今回のコアアップデートは、Googleが長年重視してきたE-A-T(専門性、権威性、信頼性)に「経験(Experience)」を加えたE-E-A-Tの重要性をさらに高めました。コンテンツの作成者がそのトピックについて実際に経験を持っているか、専門知識があるか、信頼できる情報源であるか、といった点がより厳しく評価されるようになります。
特に、YMYL(Your Money Your Life)分野においては、この傾向が顕著になるでしょう。
技術的SEOとコンテンツSEOの融合
MUVERAは、セマンティック検索の精度を向上させますが、技術的SEOの重要性が低下するわけではなく、高品質なコンテンツが適切に評価されるためには、
- サイトのクロール性
- インデックス可能性
- サイト速度
などの技術的基盤がしっかりしていることが前提となります。専門家は、技術的SEOとコンテンツSEOをこれまで以上に密接に連携させ、両輪で最適化を進めることの重要性を強調しています。
AIとSEOの共存 LLMOとAIOの台頭
MUVERAのようなAIを活用したアルゴリズムの進化に伴い、LLMO(Large Language Model Optimization)やAIO(AI Optimization)といった新たな概念も登場しています。
これは、大規模言語モデルやAIが生成するコンテンツの最適化、AIを活用したSEO戦略の構築を指します。専門家は、AIをツールとしてではなく、SEO戦略の重要な一部として、AIと共存しながら検索エンジンに評価されるコンテンツを創造していく必要性を説いています。
質の高いコンテンツが評価される傾向
MUVERA導入後の今回のコアアップデートにおいて、専門性の高い個人ブログや中小メディアが検索上位に浮上したという報告が多数あります。
これは、キーワードの網羅性やサイト規模よりも、コンテンツの質とユーザーの検索意図への合致度が重視された結果と見られています。
一方で、小手先のSEOテクニックに頼っていたサイトや、内容の薄いコンテンツを量産していたサイトは、順位を大きく落とす傾向が見られました。
Googleの新しい検索アルゴリズム「MUVERA」まとめ
Googleの新しい検索アルゴリズム「MUVERA」は、検索技術の長年の課題であった「精度と速度のトレードオフ」を解消し、検索体験を根本から変える可能性を秘めています。マルチベクトル検索の高い精度を維持しつつ、単一ベクトル検索と同等の速度を実現するFDE技術は革命的です。
これにより、より人間らしい、意図を深く理解した検索が可能になり、SEOにおいてもコンテンツの質がこれまで以上に重要になります。
2025年6月30日から7月17日にかけて展開されたGoogleコアアルゴリズムアップデートは、このMUVERAの導入と深く関連しており、実際に質の高いコンテンツが評価され、そうでないコンテンツが順位を落とすという明確な傾向が見られました。
これは、Googleが目指す「ヘルプフルコンテンツ」と「E-E-A-T」の原則が、MUVERAによってさらに強化された結果です。
MUVERAと今回のコアアップデートは、ユーザーが情報にアクセスする方法、情報と出会う方法を再定義する新時代の技術で、ウェブサイト運営者やコンテンツクリエイターは、小手先のテクニックに頼るのではなく、真にユーザーの役に立つ、価値あるコンテンツに注力する必要があります。
グラフ基盤モデル(GFM)とは? AI検索時代を勝ち抜くSEO/AIO戦略!
AIの世界は日々進化していて、新しい技術が次々と生まれています。その中でも特に注目されている「グラフ基盤モデル(GFM)」について、初心者の方にもわかりやすく解説していきます。
「グラフ」と聞くと、数学のグラフや棒グラフなどを思い浮かべるかもしれませんが、ここでいうグラフは、物事の関係性を表す特別なデータ構造のことです。
例えば、
- SNSの友達関係
- ウェブサイトのリンク
- 分子の構造
など、世の中には「つながり」でできているものがたくさんあります。GFMは、そんな「つながり」のデータをAIが賢く理解するための、まさに「新しい脳みそ」のようなものなんです。
「AI検索時代にどうすればあなたのコンテンツがAIに評価され、ユーザーに届くのか?」という視点で、GFMの理解を深めながら、SEO(検索エンジン最適化)とAIO(AI最適化)のヒントになります。
AIの進化とGFMの登場
AIの歴史を振り返ると、最初は特定のタスクしかできない専門家のようなAIが主流でした。
例えば、画像を認識するAI、文章を生成するAIなどです。
しかし、最近では「基盤モデル」という、もっと賢くて何でもこなせるAIが登場しています。これは、大量のデータで事前に学習することで、様々なタスクに対応できる汎用的な能力を身につけたAIのことです。
文章を理解したり、生成したりする「大規模言語モデル(LLM)」や、画像を扱う「大規模画像モデル(LVM)」があります。これらのモデルは、まるで人間の脳のように、一度学んだことを別の新しい問題にも応用できる「転移学習」という能力を持っています。
この「基盤モデル」の考え方を、「つながり」のデータ、「グラフデータ」に応用したのが、「グラフ基盤モデル(GFM)」です。GFMは、グラフデータに特化した基盤モデルとして、これまで難しかった複雑な関係性の理解や予測を可能にします。
SEO/AIOの視点
「基盤モデル」は、AI分野における最新かつ最も影響力のあるトレンドの一つです。このキーワードを適切に含めることで、検索エンジンやAIアシスタントがコンテンツを関連性の高い情報として認識しやすくなります(エンティティを高める)。
AI検索では「概念」や「トレンド」に対する理解度がコンテンツの評価に直結するため、重要なキーワードは明確に提示することがAIOの基本です。
GFMの「汎用性」と「適応力」
GFMのすごいところは、「汎用性」と「適応力」にあります。
- 大規模なグラフデータから学ぶ:GFMは、膨大な量のグラフデータから、共通するパターンや法則を自動的に見つけ出します。人間では気づかないような深い洞察を得られます。
- どんなグラフにも対応できる:一度学習すれば、新しい種類のグラフデータにも柔軟に対応できます。SNSの友達関係で学んだ知識を、今度は商品の購入履歴のつながりに応用するといったことが可能です。これは、GFMが「汎用的な表現」を学習するからです。
- つながりを理解する力:GFMは、グラフの「つながり方」を深く理解します。誰と誰がつながっているか、そのつながりは強いのか弱いのか、といった情報を正確に捉えることで、より賢い判断ができるようになります。
- 少ないデータでも学習できる(フューショット・ゼロショット学習):通常、AIはたくさんのデータがないと学習できませんが、GFMは事前に大量のグラフデータで学習しているため、新しいタスクに取り組む際に、少しのデータ(フューショット学習)や、全くデータがなくても(ゼロショット学習)、ある程度の予測ができます。これは、GFMが「グラフの常識」を身につけているからです。
SEO/AIOの視点
「GFMができること」というユーザーの具体的な疑問に答える形で情報を整理しています。箇条書きや太字を活用することで、AIがコンテンツの主要なポイントを抽出しやすくなり、ユーザーも短時間で情報を把握できます。SEOでは「ユーザーの検索意図」に合致するコンテンツが評価されますが、AIOではさらに「AIが情報を効率的に理解できる構造」が求められます。
GFMが解決する課題
GFMが登場するまで、グラフデータをAIで扱うのはとても大変でした。
データの中身がバラバラ(特徴量の異種性)
グラフの「ノード(点)」や「エッジ(線)」には、それぞれ異なる種類の情報が含まれます。
SNSのグラフなら、
ノードは「人」で、その人の「年齢」や「趣味」といった情報(特徴量)を持っています。
エッジは「友達」という関係性で、その関係の「強さ」といった情報を持つかもしれません。
これらのバラバラな情報をAIがまとめて理解するのは難しい課題でした。
つながり方が複雑(構造の異種性)
グラフのつながり方は、SNSのように密なものもあれば、学術論文の引用関係のように疎なものもあります。つながりの方向があったり(フォロー・フォロワー)、重みがあったり(親友・知り合い)と、非常に多様です。GFMは、このような複雑な構造の違いにも対応できる必要があります。
いろんなタスクに対応(タスクの異種性)
GFMは、ノードの分類(この人はどんなタイプ?)、リンクの予測(この人たちは友達になる?)、グラフ全体の分類(この分子はどんな性質?)、新しいグラフの生成(こんな分子を作れる?)など、様々なタスクをこなすことが期待されています。それぞれのタスクには異なるゴールと評価方法があるため、一つのモデルで全てに対応するのは大きな挑戦です。
SEO/AIOの視点
課題を明確に提示し、GFMによってどのように解決されるのかを示すことで、コンテンツの専門性と網羅性が向上します。SEOにおける「トピックカバレッジ」の向上に繋がり、AIOにおいてはAIがコンテンツの「問題解決能力」を評価する上で重要な要素となります。読者の疑問を先回りして解決する構成は、ユーザー体験の向上にも寄与します。
GFMの仕組みと3つの要素で「つながり」を理解するAIの秘密
GFMは、大きく分けて3つの要素で構成されています。これらが連携することで、複雑なグラフデータを賢く処理します。
バックボーンアーキテクチャ(AIの骨格)
これは、GFMの「脳みそ」の基本的な構造です。
- グラフモデルベース:グラフに特化したAIの技術(GNN)を骨格として使います。グラフのつながり方を直接的に学習するのが得意です。
- 言語モデルベース:文章を扱うAI(LLM)を骨格として使います。グラフの情報を文章のように変換してLLMに学習させることで、LLMの理解力をグラフデータに応用します。
- グラフ・言語共同トレーニング:GNNとLLMの両方を組み合わせることで、グラフの構造的な情報と、ノードやエッジに付随するテキスト情報の両方を同時に学習します。これが最も強力なアプローチとされています。
事前学習戦略(賢くなるための勉強法)
GFMが賢くなるための「勉強法」です。大量のグラフデータを使って、どんなことを学ぶかによって、いくつかの方法があります。
- 教師あり学習:正解データ(ラベル)があるグラフデータを使って学習します。「このつながりは友達関係である」という正解を教えて学習させます。
- 生成学習:グラフの一部を隠したり、新しいグラフを生成させたりすることで学習します。グラフの欠けている部分を予測させたり、新しい分子構造を生成させたりします。これにより、ラベルがなくても学習が進められます。
- 対照学習:似ているグラフと似ていないグラフを区別するように学習します。これにより、グラフの「似ている度合い」をAIが理解できるようになります。
適応メカニズム(新しい問題への対応力)
事前学習で得た知識を、具体的なタスクに応用するための方法です。
- ファインチューニング:事前学習で得た知識をベースに、特定のタスクの少量のデータで微調整します。一般的なSNSのグラフで学習したGFMを、特定の企業の顧客関係グラフに微調整するといった具合です。
- プロンプティング:自然な言葉でAIに指示を与えることで、新しいタスクをこなさせます。「このグラフの中で、最も影響力のある人物は誰ですか?」と質問するだけで、GFMが答えてくれるようなイメージです。
- インコンテキスト学習:いくつかの例を見せるだけで、新しいタスクを学習させます。「AとBは友達、CとDは友達。ではEとFは?」といった具合に、例から法則を学ばせます。
SEO/AIOの視点
専門的なGFMの仕組みを「AIの骨格」「勉強法」「対応力」といった平易な言葉に置き換えて解説しています。専門用語を避けつつ、正確に伝えることで、初心者にも理解しやすいコンテンツになります。また、各項目を小見出しで構造化することで、AIがコンテンツの階層構造を理解しやすくなり、SEOとAIOの両面で有利に働きます。
GFMの未来と可能性
GFMはまだ新しい技術ですが、その可能性は無限大です。
- 医療・創薬:分子構造のグラフから新しい薬の候補を見つけたり、病気の原因となる遺伝子のつながりを特定
- 金融:不正取引のネットワークを分析して詐欺を検出したり、株価の変動パターンを予測
- ソーシャルメディア:ユーザー間の関係性を深く理解して、よりパーソナライズされた情報を提供したり、フェイクニュースの拡散を防いだり。
- 交通・物流:道路網の渋滞予測や、最適な配送ルートの計画など。
GFMにはまだ「もっと賢く、もっと速く」といった課題も残されていますが、私たちの社会をより豊かに、より便利にするための強力なツールとなるでしょう。
SEO/AIOの視点
GFMがどのような分野で活用されるかを具体的に示すことで、読者は自分事として技術の重要性を理解しやすくなります。これは、読者のエンゲージメントを高め、滞在時間を延ばす効果が期待できます。AI検索では、単なる情報提供だけでなく、その情報が「どのように役立つか」という実用的な側面も評価される傾向にあります。
GFMとAI検索時代を乗りこなすためのヒント
GFMは、複雑な「つながり」のデータをAIが理解するための画期的な技術であり、今後のAIの進化を牽引する重要な存在です。
ブログで重要なのは、「ユーザーの疑問に明確に答えること」「情報を構造化すること」「専門用語を平易に解説すること」です。これらを意識することで、コンテンツは検索エンジンだけでなく、AIアシスタントからも高く評価されるようになります。
エンティティ
「エンティティ」とは、検索エンジンやAI(特にLarge Language Model:LLM)が認識する「実体」や「概念」を指します。
- 人名
- 企業名
- 場所
- 製品
- 抽象的なアイデア
など、明確に区別可能な対象を意味します。
Googleは「ナレッジグラフ」を通じて、様々なデータポイントを相互接続し、エンティティを定義しています。
LLMO(Large Language Model Optimization:AI検索最適化)対策では、このエンティティを強化・管理することが最重要視されており、構造化データの実装やコンテンツの関連付けを通じて、AIが自社の存在や専門性を正確に理解・引用しやすくする基盤となります。
関連記事






閲覧ありがとうございました。
*****************
中年独身男のお役立ち情報局
Friends-Accept by 尾河吉満
*****************

