

【AI初心者向け】
無料で始められるローカルLLM導入ガイド
2026年現在、AI技術は急速に普及し、私たちの生活や業務に不可欠なものとなりました。
しかし、ChatGPTやGeminiなどのクラウド型AIサービスを利用する企業や個人が増える一方で、「データのプライバシー」や「ランニングコスト」に対する懸念も高まっています。
そこで注目されているのが、自分のPCや社内サーバーでAIを動かす「ローカルLLM(Large Language Model;大規模言語モデル)」です。
インターネットに接続せず、機密情報を外部に出すことなく、無料で高性能なAIを利用できる手法として注目を集めており、多くのエンジニアやビジネスパーソンが導入を始めています。
そこで本記事は、初心者の方でも迷わずにローカルLLM環境を構築しできるように、
- ローカルLLMの概要
- おすすめのツール
- 具体的な導入手順
- AIの回答精度を高めるRAG(検索拡張生成)の活用法
など、最新のAI活用を始められるよう丁寧に解説します。
ローカルLLMとは?プライバシーとコストの最適解
ローカルLLMとは、インターネット上のサーバーではなく、自分のPC(ローカル環境)で動作させるAIモデルのことで、AIの民主化によって、自分のPCにダウンロード・インストールできる時代です。データを外部に送信しないため、情報漏洩のリスクを排除できる点が最大のメリットです。
クラウド型AIと比較した際の主な特徴を下記の表にまとめました。
| 特徴 | クラウド型AI | ローカルLLM |
| データ安全性 | データが運営企業に送信される (学習利用されるリスクあり) |
外部送信なし (完全オフライン可) |
| コスト | 月額サブスクリプション API従量課金 |
原則無料 (電気代のみ) |
| カスタマイズ | 制限がある | 自由自在 (モデルや設定の変更、調整が可能) |
| 必要な機器 | スマホや普通のPC | 高性能なGPU搭載PCが必要 |
| 導入難易度 | 非常に簡単 | やや難しい |
ローカルLLMは、「誰にも見られずに、どんな情報でもAIに相談できる」という安心感と、「自分の用途に合わせてAIを自由にカスタマイズできる」という柔軟性を両立します。
【導入に必要なPCスペック】モデルサイズ別推奨ハードウェア
ローカルLLMを快適に動かすには、PCの性能、特にGPU(グラフィックボード)のビデオメモリ(VRAM)が重要です。
モデルの規模(パラメータ数)によって必要なスペックが大きく異なります。
| モデル規模 (パラメータ数) |
主なモデル例 | VRAM容量 | システムメモリ (RAM) | 用途 |
| 軽量 (~8B) |
Llama 8B Gemma 8B | 8GB以上 | 16GB以上 | 日常会話、簡単な要約、コーディング支援 |
| 中規模 (13B~14B) |
Mistral12B Qwen 14B |
16GB以上 | 32GB以上 | より高度な推論、複雑なタスク、日本語精度向上 |
| 大規模 (70B以上) |
Llama 70B | 24GB以上×2 | 64GB以上 | 研究開発、最高精度の文章生成 |
【おすすめツール選定】Ollama / AnythingLLM / LM Studio
以前は複雑なプログラミング環境(Pythonなど)の構築が必要でしたが、現在ではインストールするだけで簡単にLLMを使えるツールが登場しています。初心者から上級者まで、目的別におすすめのツールを紹介します。
| ツール名 | 特徴 | 初心者 | 上級者 | RAG機能 |
| AnythingLLM | 完全GUIのオールインワン。LLM実行、ベクトルDB、チャットUIが統合。 | ◎ (最も簡単) |
△ | 内蔵 (ドキュメント管理に特化) |
| Ollama | コマンドラインベース。動作が軽快で安定。API連携に強く、RAGのバックエンドとして業界標準。 | △ | ◎ (連携・カスタマイズ性) |
LlamaIndex等との連携が必要 |
| LM Studio | GUI操作でモデルの検索・ダウンロード・実行が可能。Hugging Face連携が強力。 | ○ | ○ | 内蔵 (Big RAGプラグイン等) |
初心者の方には、GUI(グラフィカル・ユーザー・インターフェース)で直感的に操作でき、RAG(Retrieval-Augmented Generation)機能が内蔵されているAnythingLLMがおすすめです。



【2026年最新トレンド】おすすめのLLMモデルと日本語対応
代表的なLLM
ローカルLLMで利用できるモデルは多岐にわたりますが、特に日本語での利用を考慮した、2026年現在の最新トレンドモデルを紹介します。
| モデル名 | 開発元 | 特徴・強み | 日本語対応 |
| Llama | Meta | 業界標準のオープンウェイトモデル。巨大なエコシステムと豊富な派生モデル。 | 〇 (Llama 3.1以降、多言語性能が大幅強化) |
| Phi-4 | Microsoft | 14Bパラメータの「SLM(小規模言語モデル)」。数学・推論・コーディングで高性能。 | 〇 (日本語強化版も存在) |
| Gemma 3 | Gemini 2.0の技術を継承。軽量モデルから高性能モデルまで幅広く、ネイティブマルチモーダルに対応。 | ◎ (高い日本語能力) | |
| gpt-oss | OpenAI | OpenAIが公開したオープンウェイトモデル。推論性能が高く、20Bモデルは低スペックPCでも動作可能。 | 〇 (高い推論能力) |
| Qwen 3 | Alibaba | 日本語を含む119言語に対応。長文処理(最大256Kトークン)と日本語能力が非常に高い。 | ◎ (国産モデルに匹敵) |
| DeepSeek R1 | DeepSeek | 推論能力に特化。思考プロセスを出力し、数学や論理パズルで高い性能を発揮。 | 〇 (論理的な日本語回答が可能) |
| Mistral | Mistral AI | フランス発。効率性とコストパフォーマンスに優れる。Mistral NeMoは12Bながら非常に高性能。 | 〇 (多言語対応を重視) |
- 日本語の精度を重視するなら:Qwen 3 または Gemma 3
- PCスペックが低いなら:Phi-4 や Llama 3 8B の量子化モデル
- 推論・コーディングを試したいなら:DeepSeek R1やgpt-oss
その他モデル
RakutenAI-7B (RakutenAI-7B-instruct / RakutenAI-7B-chat)
- 日本企業・楽天が公開している 日本語に強い7Bモデル AIBase Model Library+1
- 指示応答(instruct)やチャットチューニング済みなので 対話・質問応答が素直で扱いやすい
- オープンソース・Apache 2.0 ライセンスで安心
初めて日本語モデルを触るなら、これを基準に選べばOKレベル。
ELYZA-japanese-Llama-2-7b
- 東京大学松尾研究室発の日本語特化モデル OpenBridge株式会社+1
- GPT-3.5相当の日本語対話性能
- 言語理解・文脈追従が比較的高いと評価あり
丁寧な日本語応答が欲しい人向け。
Vecteus-v1 / Ninja-v1
- 日本語チューニングされたモデル群 AIV
- Mistral7Bベースで 日本語の文脈を扱う力が強め
- 商用利用可能なモデルもある
少し個性的で性能高めな選択肢。
Japanese-StableLM-instruct-beta-7B
- StabilityAI系の 日本語チューニング版モデル Hugging Face
- 語彙・指示理解がそこそこ良い
- quantized(軽量化)版もあるので 低スペックPCでも動かしやすい
CPU環境でも動きを重視する人に最適。
【RAG(検索拡張生成)の深掘り】データ活用の鍵
ローカルLLMの真価は、RAGによって発揮されます。RAGは、AIが回答を生成する前に、指定されたドキュメントの中から関連情報を検索し、その内容を根拠として回答を生成する仕組みです。AIが知らない最新情報、社内マニュアル、個人のメモといったプライベートな知識について、ハルシネーション(嘘)なく正確に答えることが可能になります。
RAGは、下記の5つの基本ステップで実現されます。
- データ準備 (Loading):PDFやWordなどのドキュメントを読み込む。
- 分割 (Chunking):長い文章をAIが処理しやすい適切な長さ(チャンク)に分割する。
- ベクトル化 (Embedding):分割された文章を、AIが理解できる数値の列(ベクトル)に変換する。
- 保存 (Storing):ベクトル化されたデータをベクトルデータベース(ChromaDBやFaissなど)に保存する。
- 検索と生成 (Retrieval & Generation):質問に関連するベクトルをデータベースから検索し、LLMに渡して回答を生成させる。
【究極のカスタマイズ】設定とトラブルシューティング
より快適に、高精度にローカルLLMを利用するための設定と、よくあるトラブルの解決策を紹介します。
量子化(Quantization)によるパフォーマンス向上
ローカルLLMを快適に動かすための最も重要な技術が量子化です。AIモデルは非常に巨大なデータ(FP16やFP32)で構成されていますが、これをQ4(4ビット)やQ8(8ビット)といった形式に圧縮することで、精度をほとんど損なうことなくメモリ使用量を半分以下に削減できます。
- Q4_K_M (4ビット量子化):バランスが良く、VRAM容量が限られる場合に最も推奨される設定です。
- Q8_0 (8ビット量子化):精度重視ですが、メモリを多く消費します。
OllamaやLM Studioでは、モデル名の後ろに「Q4_K_M」などを付けてダウンロードすることで、量子化モデルを簡単に利用できます。
ハルシネーション対策と日本語設定
RAGの精度が低い、AIが嘘をつく(ハルシネーション)といった問題は、下記の設定で改善できます。
| 問題 | 解決策 |
| ハルシネーション | チャンクサイズ(文章の切り分けサイズ)を調整する、検索上位件数(top_k)を増やして参照データを増やす。 |
| 日本語の精度 | システムプロンプトに「あなたは優秀な技術アシスタントです。回答は常に日本語で行ってください」と明記する。 |
| 動作が重い | パラメータ数の少ないモデル(8Bなど)に変更するか、より強力な量子化モデル(Q3など)を試す。 |
AnythingLLMで始めてみる!
ローカルLLMを導入する際、チャットをするだけでなく、自分の持っているPDFやメモをAIに参照させたい(RAG)と考えるはずです。そこでおすすめなのが、AnythingLLMというツールです。

RAG(検索拡張生成)とは?
RAGは、AIが回答を生成する前に、指定されたドキュメントの中から関連する情報を検索し、その内容に基づいて回答する仕組みです。これにより、AIが知らない最新情報や、あなただけが持っているプライベートな知識について正確に答えることが可能になります。
AnythingLLMが初心者におすすめな理由
- オールインワン:LLMの実行エンジン、ベクトルデータベース、チャットUIがすべて統合されています。
- GUI操作:難しいコマンド入力は不要で、マウス操作だけで設定が完結します。
- 柔軟な連携:内蔵エンジンだけでなく、OllamaやLM Studioといった他のツールとも簡単に連携できます。
導入手順(ステップバイステップ)
それでは、実際にAnythingLLMを使ってローカルLLM環境を構築してみましょう。
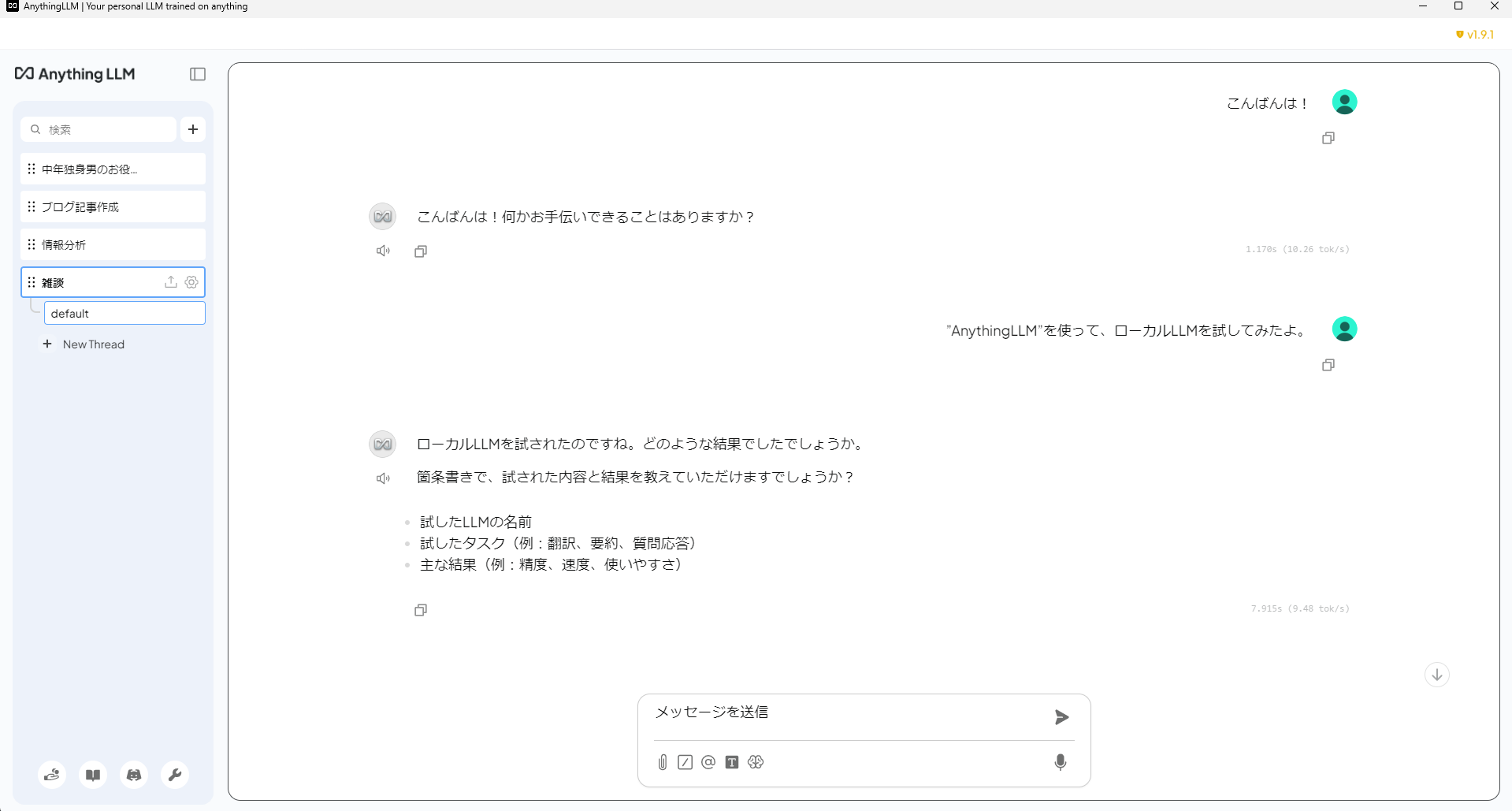
初期設定
初めて起動すると、セットアップウィザードが表示されます。
- LLM Engineの選択:初心者の方は、AnythingLLMに内蔵されている「AnythingLLM Desktop」を選択するのが最も簡単です。
- モデルの選択:推奨されるモデル(Llama 3やGemma 3など)を選択してダウンロードします。日本語に強いモデルを選びたい場合は、後から追加することも可能です。
ワークスペースの作成
AnythingLLMでは、プロジェクトごとに「ワークスペース」を作成して管理します。
画面左側の「+」ボタンをクリックし、新しいワークスペース名(例:「仕事用」「趣味のメモ」など)を入力して作成します。
【RAGの実践】自分専用の知識ベースを作る
ワークスペースを作成したら、そこに自分のドキュメントを読み込ませてみましょう。
- ドキュメントのアップロード:ワークスペース内の「Upload」ボタンをクリックし、参照させたいPDFやテキストファイルをドラッグ&ドロップします。
- ベクトル化(Embedding):アップロードしたファイルを選択し、「Move to Workspace」→「Save and Embed」をクリックします。これにより、AIが検索可能な形式にデータが変換されます。
- チャットで質問:チャット欄で「アップロードした資料に基づいて、〇〇について教えて」と入力してみてください。AIが資料の内容を引用しながら回答してくれます。
おすすめの設定とカスタマイズ
より快適に、高精度に利用するためのポイントを紹介します。
- システムプロンプトの設定:ワークスペースの設定から「System Prompt」を編集できます。「あなたは優秀な技術アシスタントです。回答は常に日本語で行ってください」といった指示を追加することで、回答の質が安定します。
- 埋め込みモデル(Embedding Model)の変更:RAGの検索精度を左右するのが埋め込みモデルです。デフォルトでも動作しますが、日本語に特化したモデル(例:multilingual-e5系)を利用すると、検索精度が向上します。
- 量子化モデルの活用:PCのスペックが限られている場合は、モデルのサイズを軽量化した「量子化(Quantized)」モデル(4-bitや8-bit)を選択することで、動作を軽くできます。
まとめ
ローカルLLMの導入は、かつては専門知識が必要な高いハードルがありましたが、AnythingLLMのような優れたツールの登場により、今や誰でも数分で自分専用のプライベートAIを構築できるようになりました。
プライバシーを完全に守りながら、自分の知識を無限に拡張してくれるパートナーとして、ローカルLLMの世界をぜひ体験してみてください。
まずは手元のドキュメントを一つ読み込ませることから始めてみましょう!
関連動画
閲覧ありがとうございました。
*****************
中年独身男のお役立ち情報局
Friends-Accept by 尾河吉満
*****************

