次世代AI【世界モデル】
日本が掴むべき千載一遇のチャンス
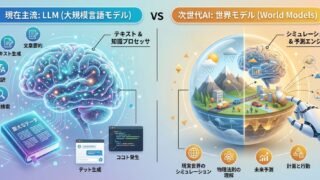
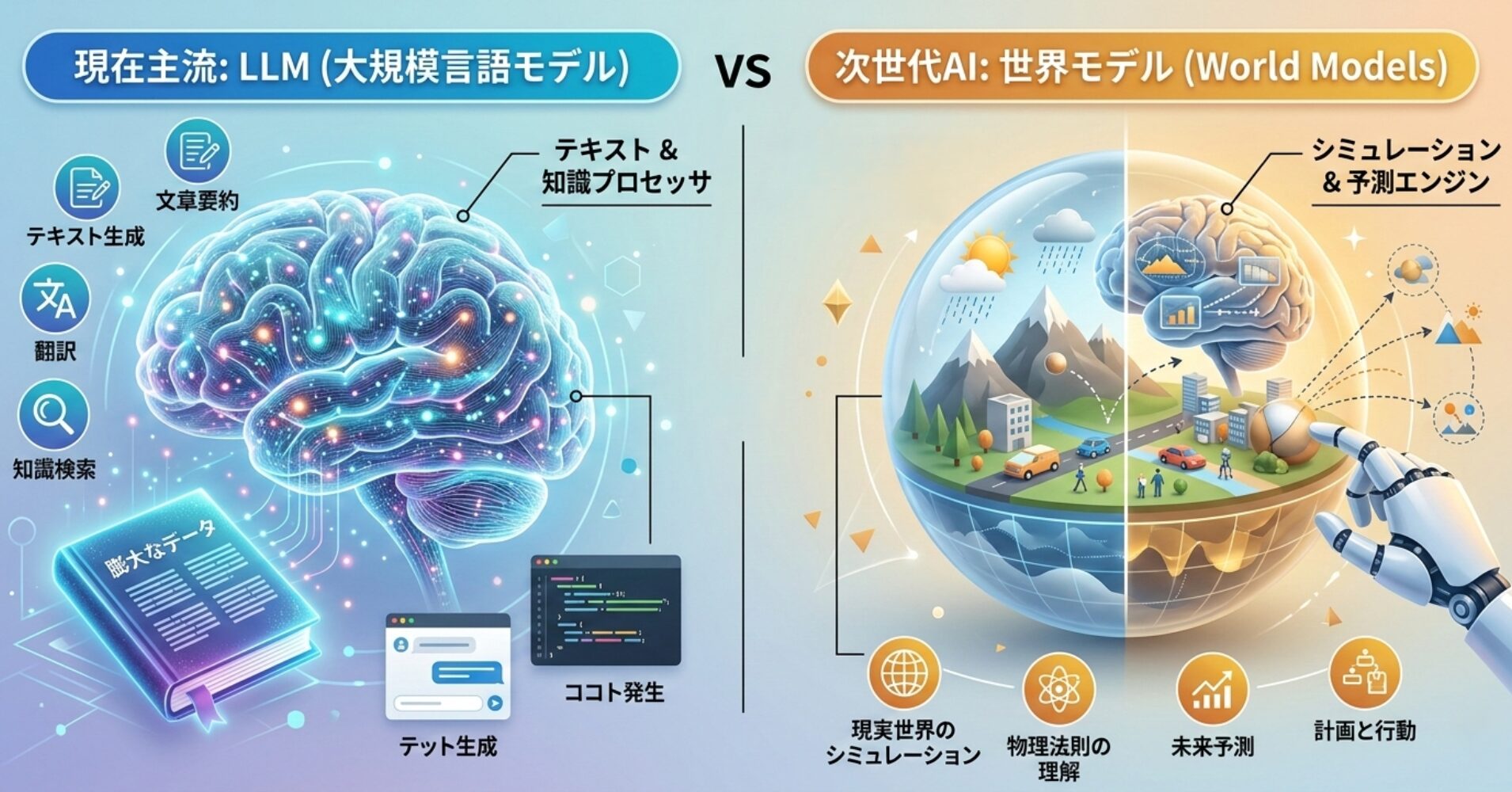
ChatGPTに代表されるLLM(大規模言語モデル)が主役でしたが、次の主役として「世界モデル(World Models)」という言葉が注目を集めています。
「世界モデル」は、AIの進化形ではなく「言葉」の壁を越え、私たちが生きる「現実世界」の仕組みを理解し始めるために必要なんです。
そこで本記事では、世界モデルの定義からLLMとの決定的な違い、日本にとって最大のチャンスと言えるのか解説します。
【世界モデルとは何か?】AIが持つ「想像力」の正体
「世界モデル」って何?
「世界モデル」とは、「現実世界の物理法則や因果関係を学習し、頭の中で未来をシミュレーションするAI」のことです。
コップをテーブルの端に置けば「落ちて割れるかもしれない」と予測できるのは、私たちが経験を通じて「重力」や「衝撃」といった物理法則を無意識のうちに「頭の中のモデル」として持っているからです。予測する能力をAIに持たせようとする試みが世界モデルです。
| 特徴 | 内容 |
| 学習対象 | 映像、センサーデータ、物理的な相互作用 |
| 核心的な能力 | 「もし〜したら、どうなるか」という因果関係の理解 |
| 役割 | 現実世界のシミュレーター(仮想的な試行錯誤) |
世界モデルを搭載したAIは、実際に動く前に「こう動いたらこうなる」というシミュレーションを内部で行うことができます。現実世界での失敗を最小限に抑えて、より高度で自律的な行動が可能になります。
最新の開発状況
2026年現在、世界モデルの研究は「動画生成」から「物理世界のシミュレーションとロボティクスへの応用」へと大きくシフトしています。主要な5つのアプローチを中心に、最新の動向を整理しました。
現在、世界モデルの開発には5つのアプローチがあり、それぞれが異なる強みを持っています。
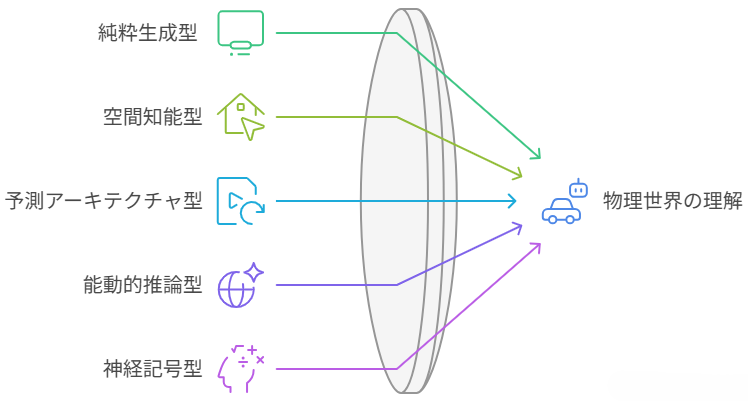
- 純粋生成型 (Transformer):Genie 3 (Google DeepMind)は、リアルタイムで操作可能な3D世界を生成。24fps/720pで動作し、一貫性のある環境を構築。
- 空間知能型 (Spatial Intelligence):Marble (World Labs / Fei-Fei Li)は、3D空間の構造を直接理解・生成することに特化。物体間の距離や配置を正確に把握。
- 予測アーキテクチャ型 (JEPA):V-JEPA / LeJEPA (Meta / AMI Labs)は、映像の欠損を予測。ピクセル単位ではなく、概念的な物理変化を学習。
- 能動的推論型 (Active Inference):AXIOM (Verses.ai / Karl Friston)は、物体を個別のエージェントとして捉え、相互作用を数理的にモデル化。自由エネルギー原理に基づく。
- 神経記号型 (Neuro-symbolic):研究段階の技術で、深層学習と論理的な記号推論を組み合わせ、物理法則を明示的に記述する試み。
注目の最新モデル
【Google DeepMind】Genie 3 & SIMA 2
Googleは、世界モデルを「AIエージェントの訓練場」として位置付けています。
【Meta / AMI Labs】V-JEPA
ヤン・ルカンが提唱するJEPA(Joint Embedding Predictive Architecture)は、従来の生成AIとは一線を画します。
- 特徴:映像のすべてを生成するのではなく、重要な「物理的な意味」だけを予測することで、計算効率が劇的に向上し、より本質的な世界の仕組みを学習できます。
【World Labs】Marble
「AIの母」と呼ばれるフェイフェイ・リが率いるWorld Labsは、空間知能を重視しています。
- 特徴:2Dの映像から3Dの空間構造を復元し、物体を自由に動かせるモデルを開発。ロボットが「どこに何があるか」を正確に把握するための基盤になります。
ロボティクス・身体化AIへの応用
最新の研究では、世界モデルをロボットの「脳」として実装する動きが加速しています。
- Sim2Realの進化:世界モデルが生成した仮想空間(シミュレーション)でロボットを数百万回訓練し、成果を現実のロボット(リアル)に適用する技術が向上しています。
- VLA (Vision-Language-Action) モデル:視覚情報と言語指示を直接ロボットの「行動」に変換するモデルです。世界モデルが「未来の予測」を担うことで、ロボットはよりスムーズで安全な動きを実現しています。
今後の展望
- リアルタイム性の向上:1秒間に数十フレームの速度で未来を予測し、即座に行動に反映させる技術が標準化されます。
- マルチモーダル化の深化:視覚だけでなく、触覚や音、物理的な「重さ」や「摩擦」の感覚を統合した世界モデルが登場しています。
- オンプレミス・ローカル化:企業の機密データ(工場の設計図や作業映像)を保護するため、クラウドではなく自社内で動く軽量な世界モデルの需要が高まっています。
従来のLLM(大規模言語モデル)との決定的な違い
現在主流のLLMと次世代の世界モデルは何が違うのでしょうか。
その違いは「何を予測しているか」に集約されます。
【予測の対象】言葉 or 物理的変化
- LLMは、膨大なテキストデータを学習して単語の次に「統計的に最も来そうな単語」を予測します。「空が」という言葉の次に「青い」が来やすいといった確率的なつながりを理解しています。
- 世界モデルは、映像やセンサーからの入力を通じて「物理的な変化」を予測します。ボールを投げたら放物線を描いて飛んでいくといった物理的な現実世界をシミュレートします。
【知能の性質】記号的 or 身体的
- LLMの知能は、「言語(記号)」の世界であるため、言語上は適切な説明ができても、実際の物理的な感覚(重さ、摩擦、距離感など)を伴わない「常識の欠如」が課題になっていました。
- 世界モデルは、「身体的な感覚」をAIに与えます。物理世界での因果関係を学ぶため、人間に近い「常識」を備えた知能へと進化します。
なぜ「世界モデル」が日本にとってチャンスなのか?
LLM(言語モデル)の分野で、アメリカや中国が圧倒的な資本力とデータ量で先行しました。しかし、物理世界を扱う「世界モデル」の領域では、日本が大きな勝ち筋を残しています。
世界最強の「リアルなデータ」を持っている
世界モデルの学習には、現実世界のデータ(ビデオ映像やセンサー情報)が不可欠です。日本は世界有数の製造業・ロボティクス大国で工場や建設現場、介護現場などで稼働するロボットから得られる「質の高いリアルなデータ」を豊富に持っています。
松尾豊教授らが提言する「国産AI戦略」
東京大学の松尾豊教授をはじめとする日本のAI研究の第一人者たちは、早くから世界モデルの重要性を説いてきました。日本政府もこの分野に注力しており、5年間で1兆円規模の投資を行うなど、官民一体となった「国産世界モデル」の開発が加速しています。
「匠の技」のデジタル化
日本が誇る熟練技能者の「勘」や「コツ」は、言葉(LLM)で説明するのは困難でした。しかし、世界モデルを使えば、熟練者の動きを映像やセンサーで捉え、「物理的な因果関係」をAIが直接学習できます。日本の伝統的な強みである「ものづくり」をAIの力で次世代に継承・進化させることができます。
世界モデルが変える私たちの未来
世界モデルが実用化されると、私たちの生活はどのように変わるのでしょうか。
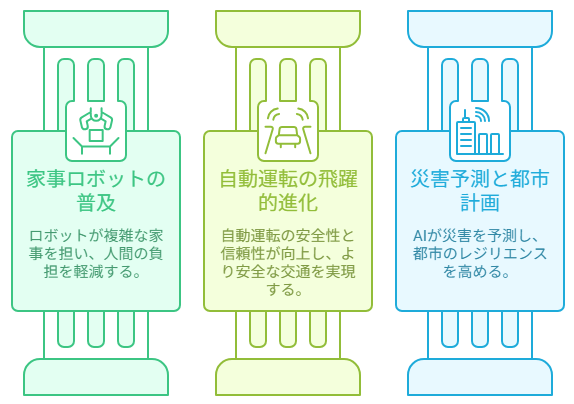
- 家事ロボットの普及:洗濯物を畳む、料理を作る、散らかった部屋を片付けるといった、複雑な物理操作が必要な家事がロボットに任せられるようになります。
- 自動運転の飛躍的進化:「もし子供が飛び出してきたら」という予測精度が劇的に向上し、より安全で信頼性の高い自動運転が実現します。
- 災害予測と都市計画:地震や洪水などの物理現象を高度にシミュレートし、被害を最小限に抑えるための最適な避難経路や都市設計が可能になります。
日本の「ものづくり」がAI時代の最強の武器になる
次世代AI「世界モデル」は、AIが「言葉」から「現実世界」に踏み込むための大きな一歩です。
言語モデルで後れを取った日本ですが、「物理」と「AI」が融合する世界モデルの領域では、いままでの「ものづくり」の蓄積が最大の武器になります。
「世界モデル」というテクノロジーの動向を注視し、日本の強みを再認識することが重要です。AIが「現実を理解する」時代、その中心に日本がいる未来はそこまで来ています。
関連記事





閲覧ありがとうございました。
*****************
中年独身男のお役立ち情報局
Friends-Accept by 尾河吉満
*****************
